Esta entrada me es especialmente útil a mí personalmente para ir de
algún modo organizando lo que voy aprendiendo. No son cosas muy complicadas,
pero mejor tenerlas todas juntas agrupadas.
A continuación enumero cuáles son
esas cosas que he ido aprendiendo:
Ø Herramientas → Opciones → Delimitadores: sirven para que el traductor establezca sus propias reglas de
segmentación.

Ø Herramientas → Contar palabras / Análisis: esta opción es bastante útil, por ejemplo, a la hora de realizar
el presupuesto de una traducción, ya que te permite calcular datos estadísticos
como contar palabras o contar el número de coincidencias parciales, exactas o
no coincidencias, en el caso de segmentos para los que no se hayan encontrado
coincidencias en la MT.

Durante
el proceso de traducción, al unir segmentos podemos encontrarnos con frases que contienen códigos ocultos, atenuados, que son, en realidad, marcas
sustitutivas de códigos de formato del texto original y que aparecen en forma
de números entre llaves, p.ej. {1}. Si un código se elimina, aparecerá
un símbolo de advertencia entre
los segmentos de origen y de destino.
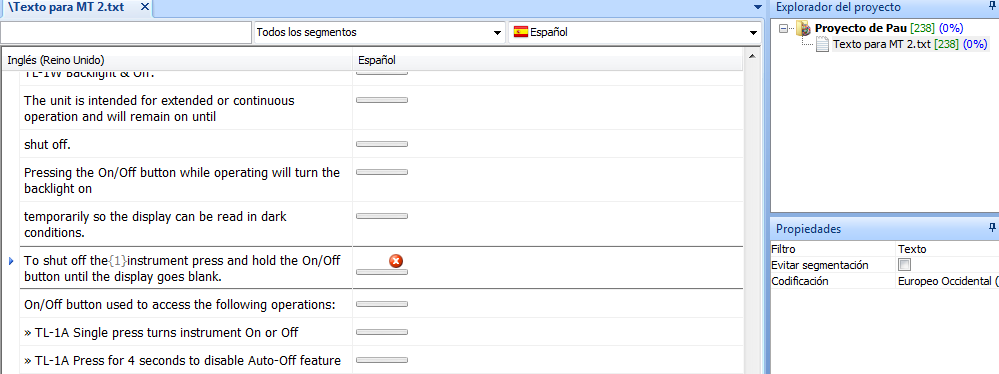
Para eliminar el símbolo de advertencia, primero hay que copiar el
código del segmento de origen en el segmento de destino.

Después, se pulsa Ctrl + Shift de nuevo y el símbolo desaparece.

Y esto es todo por hoy.


